OneHotEncoder: The Workhorse of Categorical Encoding
When I first started working with machine learning models years ago, I quickly ran into a fundamental problem: most algorithms can’t directly handle categorical data. They need numbers, not text. And that’s how my journey with categorical encoding began, eventually leading to the creation of the category_encoders library.
It’s a bit of a full-circle moment for me. As the original author of category_encoders, I watched it grow from a series of blog posts right here on this website (starting with “Beyond One Hot”) into a full-fledged library that’s now part of the scikit-learn ecosystem. While I’m no longer involved in the day-to-day maintenance of the library, which has grown far beyond what I initially envisioned, I thought it would be valuable to revisit it, this time from the perspective of a user rather than a maintainer.
In this series, I’ll walk through each encoding technique in the library, exploring their strengths, weaknesses, and implementation details. We’ll start with perhaps the most widely used: OneHotEncoder.
This is in fact the first encoder I took a look at when I started working with categorical encoding. At the time I was working a lot with fault code data, which is clearly categorical and was critically important for predictive maintenance, but extremely high cardinality (10s of thousands of unique codes). As we will see in this post, one-hot encoding is not a great fit for that, but is fantastic for other types of categorical data.
The Problem: Machines Don’t Speak Categories
Machine learning algorithms generally work with numerical data. They often can’t directly understand categorical variables like:
- Colors: “red”, “blue”, “green”
- Countries: “USA”, “Canada”, “Mexico”
- Product types: “electronics”, “clothing”, “food”
But these categorical variables often contain crucial information. So how do we transform them into something our algorithms can use? Enter one-hot encoding.
What is One-Hot Encoding?
One-hot encoding is a straightforward technique that transforms categorical variables into a format that works better with machine learning algorithms. The basic idea is:
- Create a new binary column for each unique category
- Set the value to 1 in the appropriate column and 0 in all others
For example, if we have a “color” column with values “red”, “blue”, and “green”, one-hot encoding would transform it into three columns:
| Original | color_red | color_blue | color_green |
|---|---|---|---|
| red | 1 | 0 | 0 |
| blue | 0 | 1 | 0 |
| green | 0 | 0 | 1 |
This is called “one-hot” because only one column is “hot” (has a value of 1) for each row.
Why Use One-Hot Encoding?
One-hot encoding has several advantages:
- No ordinal relationship: It doesn’t impose any artificial ordering on categories
- Distance preservation: The Euclidean distance between any two different categories is the same
- Interpretability: The resulting features are easy to understand
- Compatibility: Works with virtually all machine learning algorithms
It’s particularly useful when:
- Your categorical variable doesn’t have an intrinsic order
- You want to preserve the exact identity of each category
- You’re using algorithms that can’t handle categorical data directly (like linear regression, SVM, or neural networks)
Implementation with category_encoders
The category_encoders library provides a convenient implementation of one-hot encoding that works seamlessly with pandas DataFrames:
import pandas as pd
import category_encoders as ce
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
# Sample data
data = pd.DataFrame({
'color': ['red', 'blue', 'green', 'red', 'green', 'blue', 'red', 'green'],
'size': ['small', 'medium', 'large', 'medium', 'small', 'large', 'medium', 'small'],
'price': [10.5, 15.0, 20.0, 11.0, 19.5, 22.5, 12.0, 18.5]
})
# Initialize the encoder
encoder = ce.OneHotEncoder(cols=['color', 'size'])
# Fit and transform
encoded_data = encoder.fit_transform(data)
print(encoded_data)
This produces the following output:
color_1 color_2 color_3 size_1 size_2 size_3 price
0 1 0 0 1 0 0 10.5
1 0 1 0 0 1 0 15.0
2 0 0 1 0 0 1 20.0
3 1 0 0 0 1 0 11.0
4 0 0 1 1 0 0 19.5
5 0 1 0 0 0 1 22.5
6 1 0 0 0 1 0 12.0
7 0 0 1 1 0 0 18.5
We can visualize this encoding with a heatmap to better understand how it is representing our data:
# Visualize the encoding
plt.figure(figsize=(12, 8))
encoded_cols = [col for col in encoded_data.columns if col != 'price']
sns.heatmap(encoded_data[encoded_cols].T, cmap='Blues', cbar=False,
linewidths=1, annot=True, fmt='g')
plt.title('One-Hot Encoding Visualization')
plt.tight_layout()
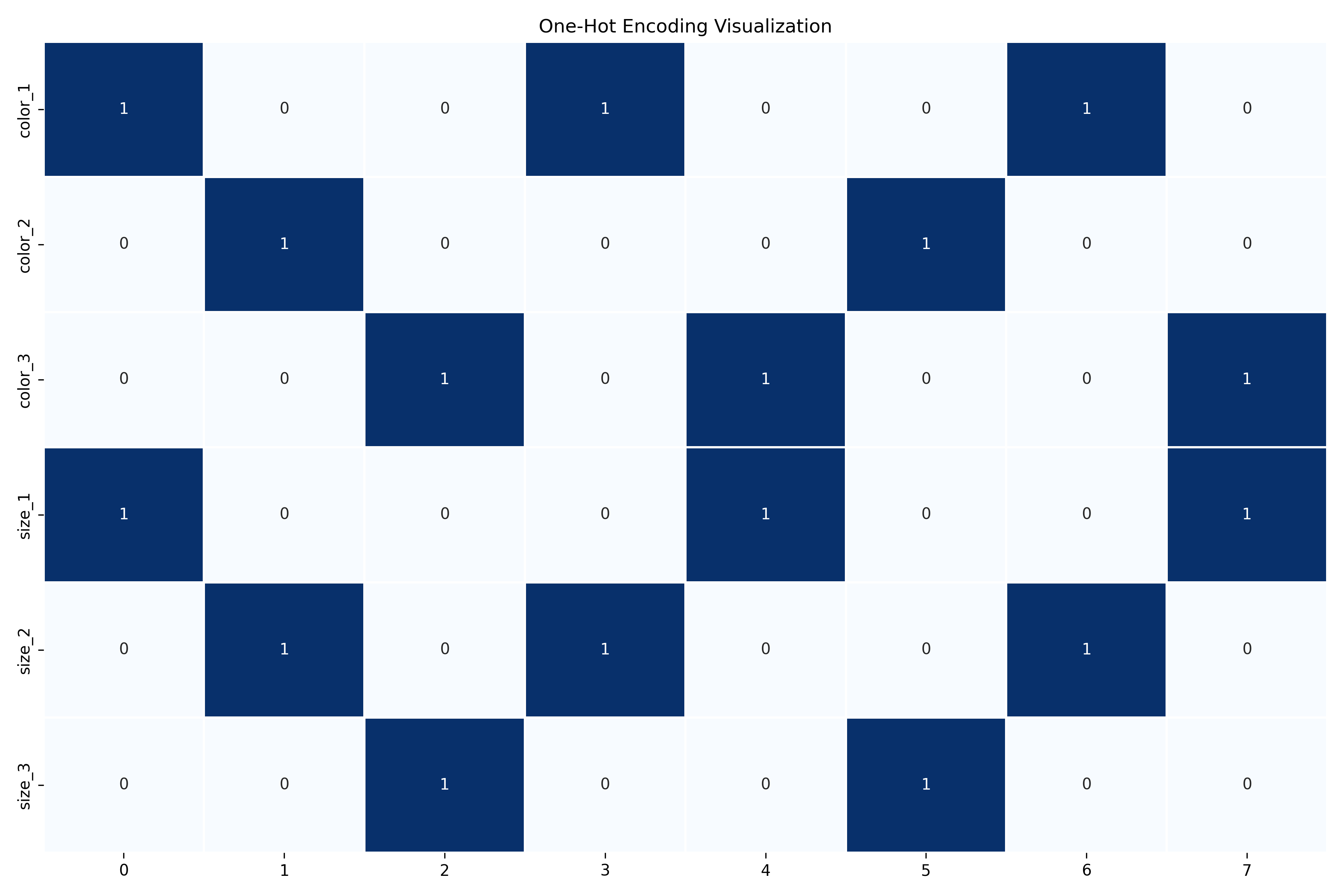
Key Features of category_encoders.OneHotEncoder
The OneHotEncoder in category_encoders offers several useful features:
1. Pandas integration
# With category_encoders, you can directly pass and receive pandas DataFrames
encoded_df = encoder.fit_transform(df)
2. Column specification by name
# Encode only specific columns by name
encoder = ce.OneHotEncoder(cols=['color', 'size'])
3. Handling unknown categories
# Handle new categories in test data that weren't in training data
encoder = ce.OneHotEncoder(handle_unknown='value')
4. Return mappings
# Get the mapping from original categories to encoded columns
mappings = encoder.category_mapping
5. Inverse transform
# Convert back to original representation
original_data = encoder.inverse_transform(encoded_data)
Real-World Example: Customer Segmentation
Let’s use OneHotEncoder in a more realistic scenario - customer segmentation. Here we are making up some data to represent customer data, but you could imagine this being actual customer data.
import pandas as pd
import category_encoders as ce
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
# Sample customer data
customers = pd.DataFrame({
'customer_id': range(1, 101),
'age': [30, 45, 22, 65, 38, ...], # Truncated for brevity
'income': [55000, 90000, 20000, 60000, 70000, ...],
'location': ['urban', 'suburban', 'urban', 'rural', 'suburban', ...],
'education': ['bachelor', 'master', 'high_school', 'phd', 'bachelor', ...],
'purchase_frequency': ['high', 'medium', 'low', 'medium', 'high', ...]
})
# Initialize the encoder for categorical columns
encoder = ce.OneHotEncoder(cols=['location', 'education', 'purchase_frequency'])
# Fit and transform
encoded_customers = encoder.fit_transform(customers)
# Now we can use this for clustering
kmeans = KMeans(n_clusters=4, random_state=42)
encoded_customers['cluster'] = kmeans.fit_predict(
encoded_customers.drop('customer_id', axis=1)
)
# Visualize the clusters
plt.figure(figsize=(10, 6))
for cluster in range(4):
cluster_data = encoded_customers[encoded_customers['cluster'] == cluster]
plt.scatter(
cluster_data['age'],
cluster_data['income'],
label=f'Cluster {cluster}'
)
plt.xlabel('Age')
plt.ylabel('Income')
plt.title('Customer Segments')
plt.legend()
plt.show()
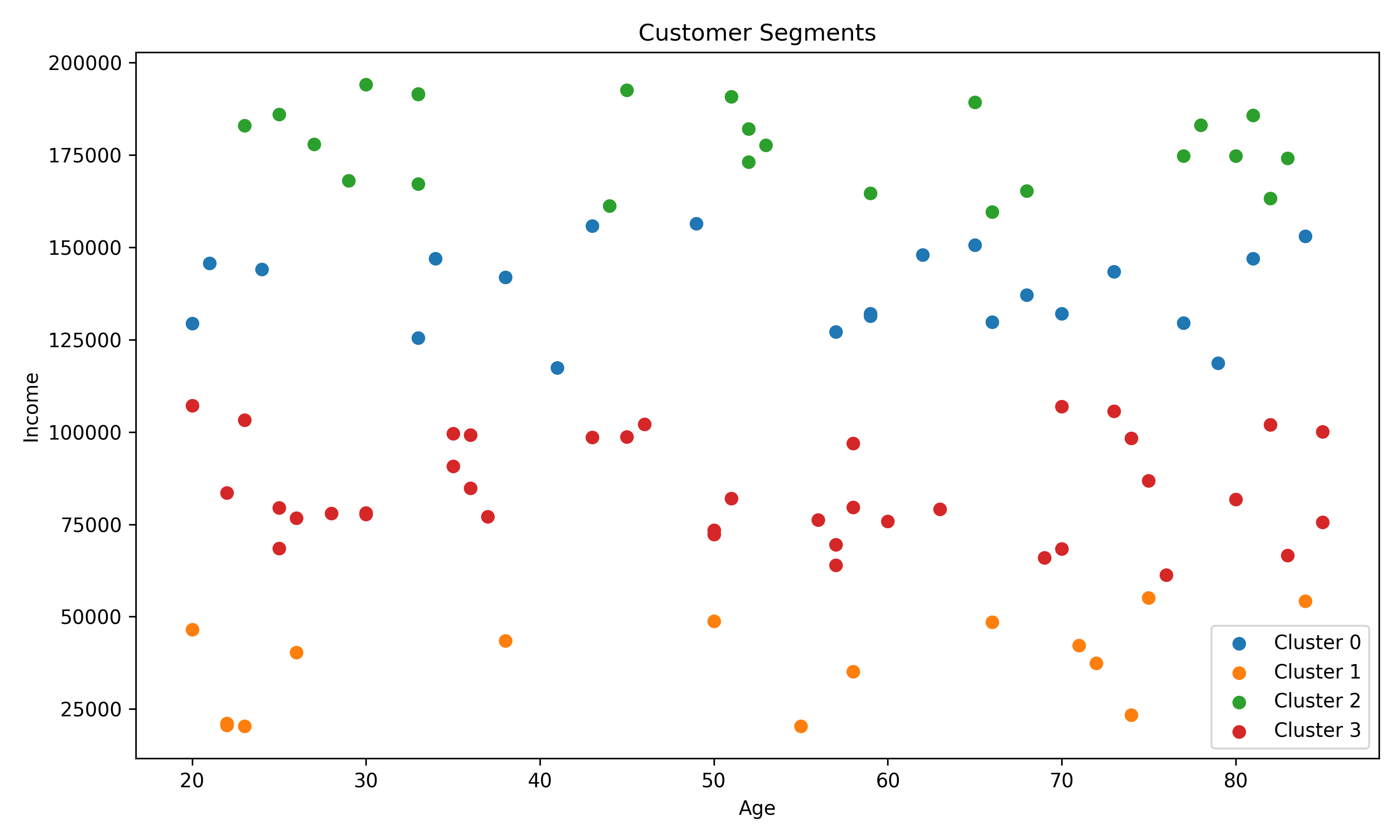
This example shows how one-hot encoding enables us to include categorical data in our clustering algorithm, potentially revealing more meaningful customer segments.
Limitations and Considerations
While one-hot encoding is powerful, it has some limitations to be aware of:
Dimensionality explosion: If a categorical variable has many unique values, one-hot encoding will create many new columns, which can lead to the “curse of dimensionality”. In extreme cases it also can just cause numerical and compute problems, you might not be able to fit all of the data in memory for extreme cardinalities.
Sparse matrices: The resulting matrix is often very sparse (mostly zeros), which can be inefficient for some algorithms, though specific implementations can help with this.
New categories: If new categories appear in your test data that weren’t in your training data, the encoder won’t have columns for them. This is where the
handle_unknownparameter comes in handy in category_encoders, but really you may need to retrain.
When to Use (and When Not to Use) One-Hot Encoding
Use one-hot encoding when:
- Your categorical variables have no intrinsic order
- The number of categories is relatively small
- You need maximum interpretability
- Your algorithm can’t handle categorical data directly
Consider alternatives when:
- You have high-cardinality features (many unique values)
- Memory or computational efficiency is a concern
- Your categorical variables have a natural ordering
- You’re working with tree-based models that can handle categories directly
Conclusion: The Reliable Workhorse
One-hot encoding remains one of the most widely used techniques for handling categorical data, and for good reason. It’s intuitive, effective, and works well with a wide range of algorithms. While it may not be the best choice for every situation, it’s often a great starting point and baseline for comparison with other encoding methods.
In the next post, we’ll explore OrdinalEncoder, which takes a different approach by assigning ordered integer values to categories.
Stay in the loop
Get notified when I publish new posts. No spam, unsubscribe anytime.