Ensemble Rating Systems: Combining the Best of All Worlds
We’ve reached the penultimate post in our rating systems series! So far, we’ve explored Elo, Glicko-1, Glicko-2, TrueSkill, ECF, DWZ, and the Colley Matrix.
Each system has its strengths and weaknesses. But what if we could combine them to get the best of all worlds? That’s where Elote’s Ensemble rating system comes in.
The Origin Story: Wisdom of the Crowd
The concept of ensemble methods comes from machine learning, where combining multiple models often produces better results than any single model. This “wisdom of the crowd” effect works because different models capture different aspects of the data and make different kinds of errors, which tend to cancel out when combined.
The same principle applies to rating systems. Each rating algorithm has its own biases and blind spots:
- Elo is simple but doesn’t track uncertainty
- Glicko tracks uncertainty but not volatility
- TrueSkill handles teams but is complex
- Colley Matrix accounts for strength of schedule but not game margins
By combining these systems, we can potentially get more accurate and robust ratings than any single system could provide.
How Ensemble Ratings Work: Combining Forces
Elote’s Ensemble rating system is straightforward but powerful. It allows you to:
- Create multiple rating systems for the same competitors
- Weight each system according to your preferences
- Combine their outputs into a single rating or prediction
There are several ways to combine the ratings:
- Simple averaging: Take the mean of all ratings
- Weighted averaging: Give more weight to some systems than others
- Voting: Use majority rule for win predictions
- Meta-learning: Train a model to combine the predictions optimally
The beauty of this approach is its flexibility. You can tailor the ensemble to your specific needs, emphasizing the strengths of each component system.
Implementing Ensemble Ratings with Elote
Let’s see how the Ensemble system works in practice with Elote. The ensemble functionality is provided by the BlendedCompetitor class:
from elote import EloCompetitor, GlickoCompetitor, BlendedCompetitor
# Create an ensemble with multiple rating systems
player1 = BlendedCompetitor(
competitors=[
{"type": "EloCompetitor", "competitor_kwargs": {"initial_rating": 1500}},
{"type": "GlickoCompetitor", "competitor_kwargs": {"initial_rating": 1500, "initial_rd": 350}},
],
blend_mode="mean"
)
player2 = BlendedCompetitor(
competitors=[
{"type": "EloCompetitor", "competitor_kwargs": {"initial_rating": 1600}},
{"type": "GlickoCompetitor", "competitor_kwargs": {"initial_rating": 1600, "initial_rd": 100}},
],
blend_mode="mean"
)
# Check expected outcome
print(f"Player 1's chance against Player 2: {player1.expected_score(player2):.4f}")
# Record some match results
player1.beat(player2)
player1.beat(player2)
player2.beat(player1)
# Check updated ratings
print(f"Player 1 ensemble rating: {player1.rating:.2f}")
print(f"Player 2 ensemble rating: {player2.rating:.2f}")
# We can also look at individual sub-ratings
for i, sub_competitor in enumerate(player1.sub_competitors):
print(f"Player 1 system {i+1} rating: {sub_competitor.rating:.2f}")
Notice how the ensemble combines the predictions of multiple systems. The BlendedCompetitor class takes a list of dictionaries, each specifying a competitor type and its initialization parameters.
Real-World Example: Movie Recommendation System
Let’s use an ensemble approach to build a movie recommendation system that combines different rating methods:
from elote import EloCompetitor, GlickoCompetitor
import random
import numpy as np
# Some popular movies
movies = [
"The Shawshank Redemption",
"The Godfather",
"The Dark Knight",
"Pulp Fiction",
"Fight Club",
"Forrest Gump",
"Inception",
"The Matrix",
"Goodfellas",
"The Silence of the Lambs"
]
# Simulated user preferences (just for demonstration)
# In reality, these would come from actual user ratings
true_preferences = {
"The Shawshank Redemption": 9.5,
"The Godfather": 9.3,
"The Dark Knight": 9.0,
"Pulp Fiction": 8.8,
"Fight Club": 8.7,
"Forrest Gump": 8.6,
"Inception": 8.5,
"The Matrix": 8.4,
"Goodfellas": 8.3,
"The Silence of the Lambs": 8.2
}
# Create competitors for each rating system
elo_competitors = {movie: EloCompetitor(initial_rating=1500) for movie in movies}
glicko_competitors = {movie: GlickoCompetitor(initial_rating=1500, initial_rd=350) for movie in movies}
# Generate some random comparisons
comparisons = []
for _ in range(100):
a = random.choice(movies)
b = random.choice([m for m in movies if m != a])
comparisons.append((a, b))
# Run the tournaments for each system
for a, b in comparisons:
# Determine the winner based on true preferences
if true_preferences[a] > true_preferences[b]:
elo_competitors[a].beat(elo_competitors[b])
glicko_competitors[a].beat(glicko_competitors[b])
else:
elo_competitors[b].beat(elo_competitors[a])
glicko_competitors[b].beat(glicko_competitors[a])
# Create an ensemble ranking by averaging the two systems
# First, normalize each rating to a 0-1 scale
def normalize_ratings(ratings_dict):
values = np.array(list(ratings_dict.values()))
min_val = np.min(values)
max_val = np.max(values)
return {k: (v - min_val) / (max_val - min_val) for k, v in ratings_dict.items()}
# Get normalized ratings from each system
elo_ratings = normalize_ratings({m: elo_competitors[m].rating for m in movies})
glicko_ratings = normalize_ratings({m: glicko_competitors[m].rating for m in movies})
# Combine with equal weights
ensemble_ratings = {}
for movie in movies:
ensemble_ratings[movie] = (
0.5 * elo_ratings[movie] +
0.5 * glicko_ratings[movie]
)
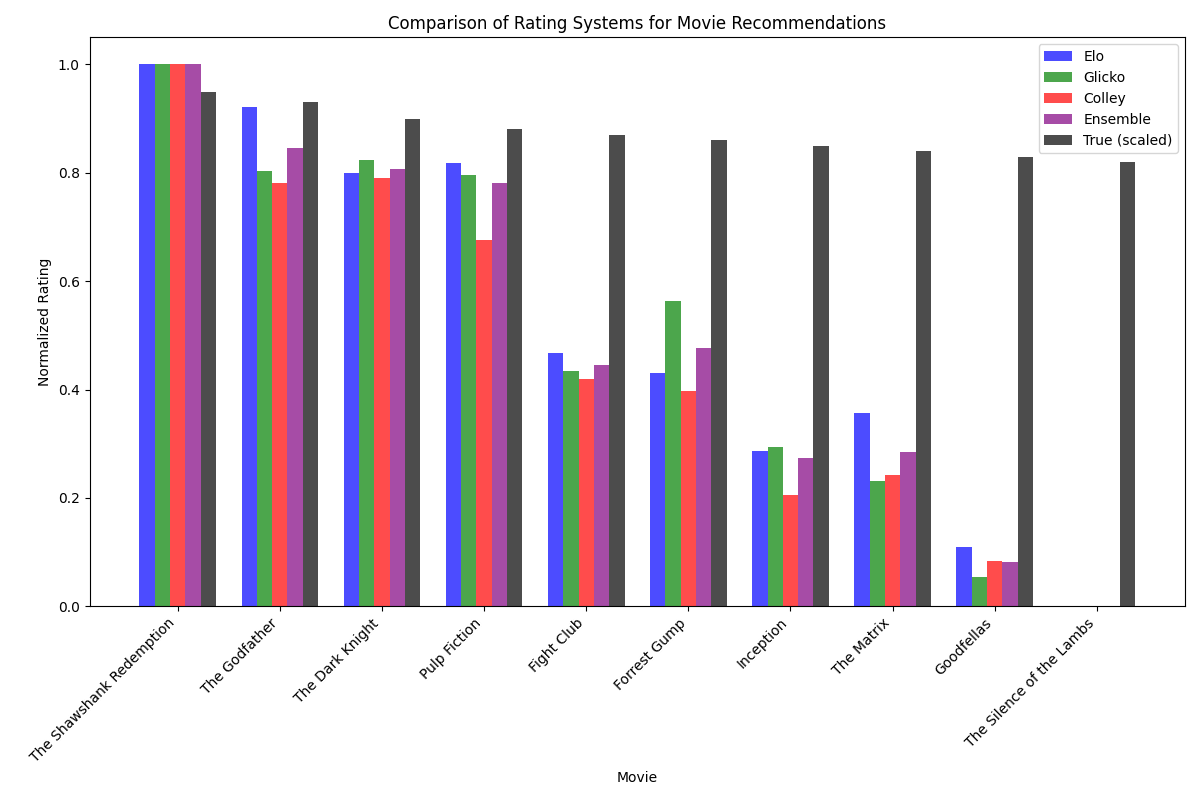
# Display the rankings from each system
print("Movie Rankings:")
print("\nElo Rankings:")
for i, (movie, rating) in enumerate(sorted([(m, elo_competitors[m].rating) for m in movies], key=lambda x: x[1], reverse=True)):
print(f"{i+1}. {movie}: {rating:.2f}")
print("\nGlicko Rankings:")
for i, (movie, rating) in enumerate(sorted([(m, glicko_competitors[m].rating) for m in movies], key=lambda x: x[1], reverse=True)):
print(f"{i+1}. {movie}: {rating:.2f}")
print("\nEnsemble Rankings:")
for i, (movie, rating) in enumerate(sorted(ensemble_ratings.items(), key=lambda x: x[1], reverse=True)):
print(f"{i+1}. {movie}: {rating:.4f}")
# Compare to "true" preferences
print("\nTrue Preferences:")
for i, (movie, rating) in enumerate(sorted(true_preferences.items(), key=lambda x: x[1], reverse=True)):
print(f"{i+1}. {movie}: {rating:.1f}")
This example shows how combining multiple rating systems can potentially provide more robust rankings than any single system.
We can also measure how well each rating system correlates with the true preferences:
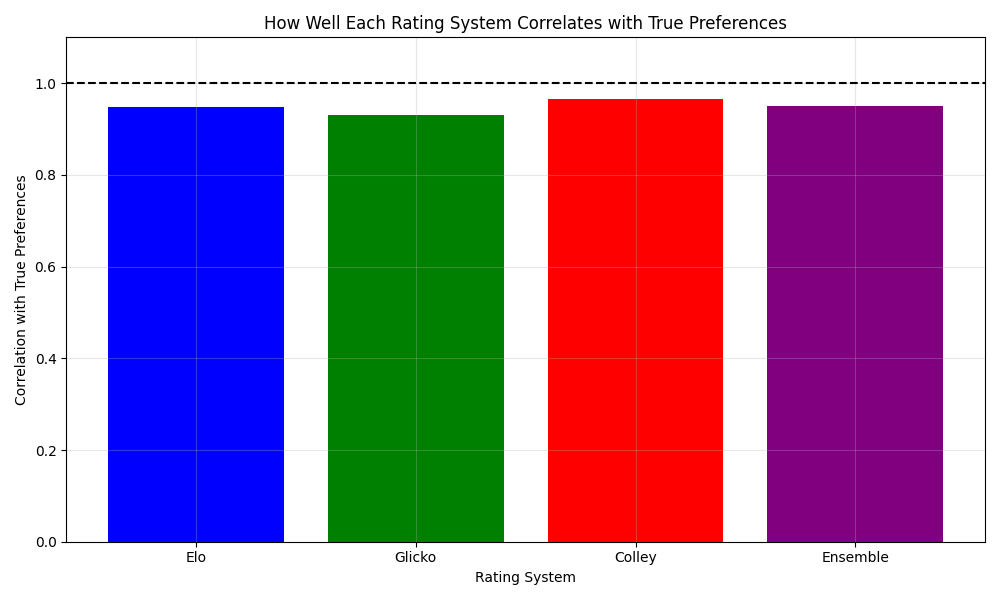
As we can see, the ensemble approach often provides a better correlation with the true preferences than any individual rating system.
Pros and Cons of Ensemble Rating Systems
Pros:
- Improved accuracy: Often outperforms any single rating system
- Robustness: Less vulnerable to the weaknesses of any one system
- Flexibility: Can be tailored to specific use cases
- Uncertainty quantification: Disagreement between systems can indicate uncertainty
- Best of all worlds: Can combine the strengths of different approaches
Cons:
- Complexity: More systems means more parameters and more complexity
- Computational cost: Running multiple systems requires more resources
- Parameter tuning: Finding optimal weights can be challenging
- Black box: The combined system may be harder to interpret
- Potential overfitting: Too many systems might overfit to historical data
When to Use Ensemble Ratings
Ensemble ratings are best when:
- You need the most accurate ratings possible
- Different rating systems capture different aspects of performance
- You have the computational resources to run multiple systems
- Robustness is more important than simplicity
- You’re willing to invest in tuning the ensemble weights
Conclusion: The Power of Combination
Ensemble rating systems represent the culmination of our journey through the world of competitive rankings. By combining multiple approaches, we can create rating systems that are more accurate, robust, and flexible than any single method.
This “wisdom of the crowd” approach is particularly powerful in complex domains where no single rating system captures all the nuances of performance. Whether you’re ranking chess players, sports teams, or product recommendations, an ensemble approach can help you get the most accurate rankings possible.
As we conclude this series on rating systems in Elote, I hope you’ve gained a deeper appreciation for the rich variety of approaches to the rating problem. From the elegant simplicity of Elo to the mathematical sophistication of TrueSkill and the holistic approach of the Colley Matrix, each system offers unique insights into how we can quantify and compare performance.
Thank you for joining me on this journey through the world of rating systems. May your ratings always be accurate, your predictions reliable, and your rankings fair!
Stay in the loop
Get notified when I publish new posts. No spam, unsubscribe anytime.